Software Bill Of Materials Formats
Categories:
Prerequisite
If you don’t understand what is Software Bill of Materials (SBOM), please read this blog post first.
Different SBOM formats comparison
The National Telecommunications and Information Administration (NTIA) in the U.S. defined minimum requirements for SBOM formats:
- Identifying the supplier of the software component.
- Identifying the details about the version of the component.
- Including unique identifiers for the component like cryptographic hash functions.
- Including the relationships between all dependencies inside the component.
- Including a timestamp of when and by whom the SBOM report was created or last modified
In this section, we discuss different kinds and formats for SBOM standards and make a brief comparison between them. Three commonly used standards achieved the NTIA minimum requirements for SBOM generation and each one results in a different final SBOM document.
1 - The Software Package Data Exchange (SPDX)
History:
SPDX is an open-source machine-readable format adopted by the Linux Foundation as an industry standard. The specifications are implemented as a file format that identifies the software components within a larger piece of computer software and fulfilling the requirements of NTIA. The SPDX project started in 2010 and was initially dedicated to solving the issues around open source licensing compliance. It evolved over the years to adhere supply chain security challenges and has seen extensive uptake by companies and projects in the software industry. Companies like Hitachi, Fujitsu, and Toshiba contributed to furthering the standard in the SPDX v2.2.2 specification release.
Specs:
The SPDX specification describes the necessary sections and fields to produce a valid SPDX document. Note that the only mandatory field in all spdx documents is the “Document Creation Information” section. The presence of other sections (and subset fields of each section) is dependent on your use case and the information you want to provide.
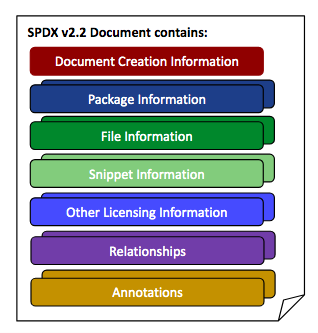
Fig 1: https://spdx.dev/wp-content/uploads/sites/41/2020/05/spdx-2.2-document.png
{kind=link}
- Document Creation Information – Denotes who created the document, how it was created, and other useful information related to its creation. It provides the necessary information for forward and backward compatibility for processing tools (version numbers, license for data, authors, etc. )
- Package Information – This section provides information about the “package”. A package can be one or more files. These files could be one or more files of any type including but not limited to source, documents, binaries, containers, and so forth. The package information contains the originator, where it was sourced from, a download URL, a checksum, and so forth. It also contains summary licensing for the package.
- File Information – This is information about a specific file. It can contain the file copyrights found in the file (if any), the license of the file, a checksum for the file, file contributors, and so forth.
- Snippet Information – Snippets can optionally be used when a file is known to have some content that has been included from another source. They are useful for denoting when part of a file may have been created under another licenseSnippet information can be used to define licensing for ranges within files.
- Other Licensing Information – Other licensing information provides a way to describe licenses that are not on the SPDX License List. You can create a local (to the SPDX document) identifier for the license and place the license text itself in the document as a well and then reference it for files just like you would a license from the license list.
- Relationships – Relationships were introduced in the 2.0 specification and are a very powerful way of expressing how SPDX documents relate to one another. See an example of how the SPDX represents those here.
- Annotations – Annotations are comments made by people on various entities and elements within the document. For example, someone reviewing the document may make an annotation about a file and its license. Annotations are useful for reviews of SPDX documents and for conveying specific information about the package, file, creation, license, file(s), etc.
In the SPDX specification release 2.2.2, additional output formats of JSON, YAML, and XML are supported. A diverse set of examples for SPDX are available on this github repo
Further information on the data model and SPDX guide can be found on the SPDX website.
Use Cases:
- SBOM for software components
- Tracking of intellectual property (licensing, copyright) of software components
- Listing contents of a software distribution
- Container contents inventory
- Associating CPEs with specific packages
- Identifying provenance of lines of code embedded in files
Key Features:
- Documented artifacts can be checked using the provided hash values
- Rich facilities for intellectual property and licensing information
- Flexible model able to scale from snippets and files up to packages, containers, and even operating system distributions
- Ability to add mappings to other package reference systems
2 - Software Identification (SWID) Tags
History:
It is a standard implemented by the National Institute of Standards and Technology (NIST) in the U.S. that was published in 2009, then revised in 2015. They were designed to provide a transparent way for organizations to track the software installed on their managed devices. Standard SWID tags are not generated at the end of certain software creation, instead, they define a lifecycle where a new SWID tag is added to an endpoint with the software installation process and is deleted with the uninstall process. When this lifecycle is followed, the presence of a given SWID Tag corresponds directly to the presence of the software product that the Tag describes.
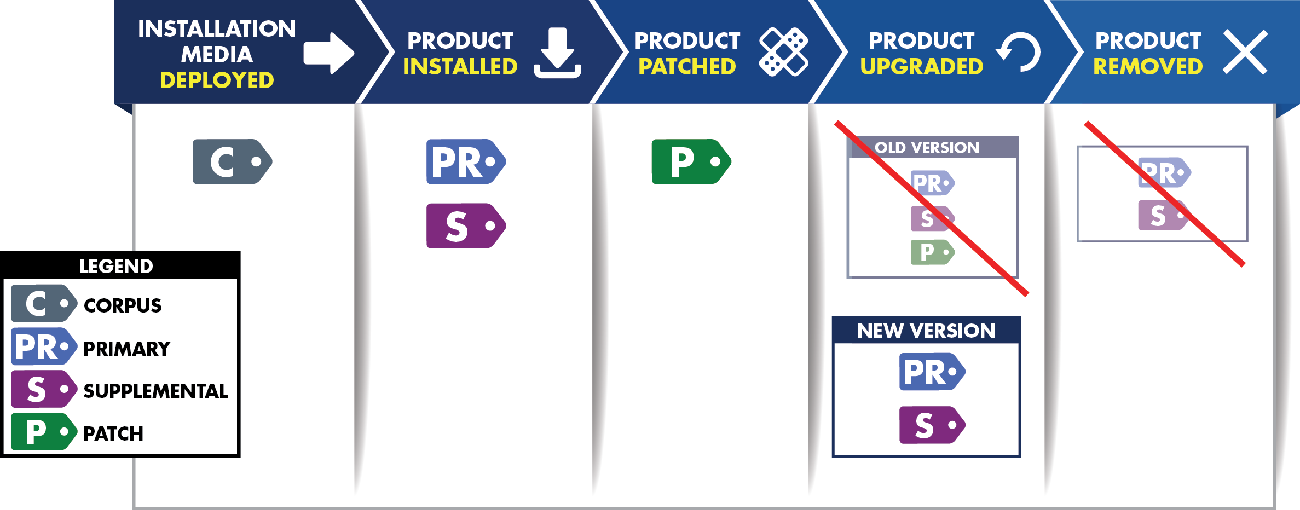
Fig 2: https://d3i71xaburhd42.cloudfront.net/496312d64dc77b223803a4ee1b717be8e528e86f/16-Figure1-1.png
{kind=link}
Note that the present SWID tags change depending on the current state of the software.
Specs:
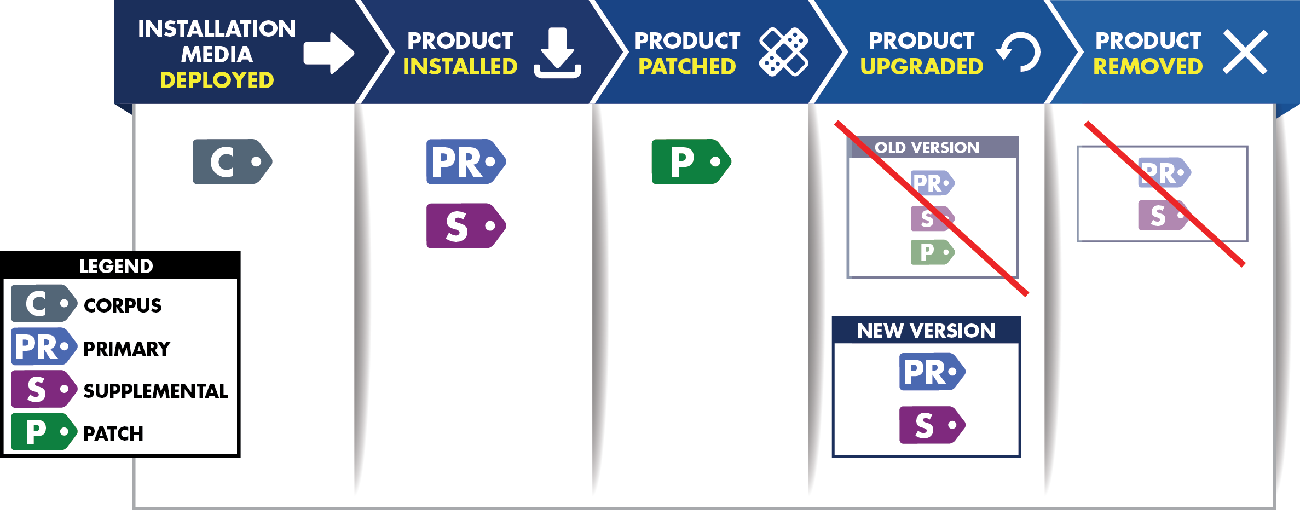
The NISTIR 8060 Guideline identifies the standards of SWID tags and the components of each tag. We here go over the necessary types mentioned in the figure above. To capture the lifecycle of a software component, the SWID specification defines four types of SWID tags: primary, patch, corpus, and supplemental
- Corpus Tag – A SWID Tag that identifies and describes an installable software product in its pre-installation state. A corpus tag can be used to represent metadata about an installation package or installer for a software product, a software update, or a patch.
- Primary Tag – A SWID Tag that identifies and describes a software product installed on a computing device.
- Supplemental Tag – A SWID Tag that allows additional information to be associated with any referenced SWID tag. This helps to ensure that SWID Primary and Patch Tags provided by a software provider are not modified by software management tools while allowing these tools to provide their software metadata.
- Patch Information – A SWID Tag that identifies and describes an installed patch that has made incremental changes to a software product installed on a computing device.
Note that Corpus, primary, and patch tags have similar functions in that they describe the existence and/or presence of different types of software (e.g., software installers, software installations, software patches), and, potentially, different states of software products. In contrast, supplemental tags furnish additional information not contained in the corpus, primary, or patch tags.
SWID tags are mainly implemented in XML format while JSON format is under development. Some tag examples can be found here
Use Cases:
- SBOM for software components
- Continuous monitoring of installed software inventory
- Identifying vulnerable software on endpoints
- Ensuring that installed software is properly patched
- Preventing installation of unauthorized or corrupted software
- Preventing the execution of corrupted software
- Managing software entitlements
Key Features:
- Provides stable software identifiers created at build time
- Standardizes software information that can be exchanged between software providers and consumers as part of the software installation process
- Enables the correlation of information related to software including related patches or updates, configuration settings, security policies, and vulnerability and threat advisories.
3 - CycloneDX
History:
CycloneDX is a lightweight SBOM standard designed for use in application security context and supply chain component analysis as it was originally intended to identify vulnerabilities and supply chain component analysis. It also supports checking for licensing compliance. The CycloneDX project was initiated in 2017 in the OWASPcommunity, then it became a dedicated open source project and included other working groups from Sonatypeand ServiceNow. Supported file formats for CycloneDX are (XML, JSON, and protocol buffers)
Specs:
CycloneDX provides schemas for both XML and JSON, defining a format for describing simple and complex compositions of software components. It’s designed to be flexible, and easily adaptable, with implementations for popular build systems. The specification encourages the use of ecosystem-native naming conventions and supports SPDX license IDs and expressions, pedigree, and external references. It also natively supports the Package URL specification and correlating components to CPEs. The CycloneDX object model is defined in the figure.

Fig 3: https://cyclonedx.org/theme/assets/images/high-level-object-model-small.svg
{kind=link}
- BOM Metadata Information – BOM metadata includes the supplier, manufacturer, and the target component for which the BOM describes. It also includes the tools used to create the BOM, and license information for the BOM document itself.
- Components Information – Components describe the complete inventory of first-party and third-party components. Component identity can be represented as: – Coordinates (group, name, version) – Package URL – Common Platform Enumerations (CPE) – SWID – Cryptographic hash functions (SHA-1, SHA-2, SHA-3, BLAKE2b, BLAKE3)
- Services Information – Services describe external APIs that the software may call. Services describe endpoint URIs, authentication requirements, and trust boundary traversals. The flow of data between software and services can also be described including the data classifications and the flow direction of each type.
- Dependency Relationships – CycloneDX provides the ability to describe components and their dependency on other components. The dependency graph is capable of representing both direct and transitive relationships. Components that depend on services can be represented in the dependency graph and services that depend on other services can be represented as well.
- Compositions – Compositions describe constituent parts (including components, services, and dependency relationships) and their completeness. The aggregate of each composition can be described as complete, incomplete, incomplete first-party only, incomplete third-party only, or unknown.
- Vulnerabilities – Known vulnerabilities inherited from the use of third-party and open source software and the exploitability of the vulnerabilities can be communicated with CycloneDX. Previously unknown vulnerabilities affecting both components and services may also be disclosed using CycloneDX, making it ideal for both VEX and security advisory use cases.
- Extensions – Multiple extension points exist throughout the CycloneDX object model allowing fast prototyping of new capabilities and support for specialized and future use cases. The CycloneDX project maintains extensions that are beneficial to the larger community. The project encourages community participation and the development of extensions that target specialized or industry-specific use cases.
Use Cases:
- Inventory of all software components.
- Identifying known vulnerabilities.
- Integrity verification using the hash functions.
- Authenticity of the software components using a digital signature.
- License compliance
- Provenance
Generate SBOMs manually? definitely not
SBOMs are frequently updated with each release of the software, so we need tools and packages to be integrated with our ci/cd pipeline. We talk about this here