Overview
What is Jenkins X?
Jenkins X is designed to make it simple for developers to work to DevOps principles and best practices. The approaches taken are based on the comprehensive research done for the book ACCELERATE: Building and Scaling High Performing Technology Organisations. You can read why we use Accelerate for the principles behind Jenkins X.
“DevOps is a set of practices intended to reduce the time between committing a change to a system and the change being placed into normal production, while ensuring high quality.”
The goals of DevOps projects are:
High performing teams should be able to deploy multiple times per day compared to the industry average that falls between once per week and once per month.
The lead time for code to migrate from ‘code committed’ to ‘code in production’ should be less than one hour and the change failure rate should be less than 15%, compared to an average of between 31-45%.
The Mean Time To Recover from a failure should also be less than one hour.
Jenkins X has been designed from first principles to allow teams to apply DevOps best practices to hit top-of-industry performance goals.
The following best practices are considered key to operating a successful DevOps approach:
Jenkins X brings together a number of familiar methodologies and components into an integrated approach that minimises complexity.
Jenkins X builds upon the DevOps model of loosely-coupled architectures and is designed to support you in deploying large numbers of distributed microservices in a repeatable and manageable fashion, across multiple teams.
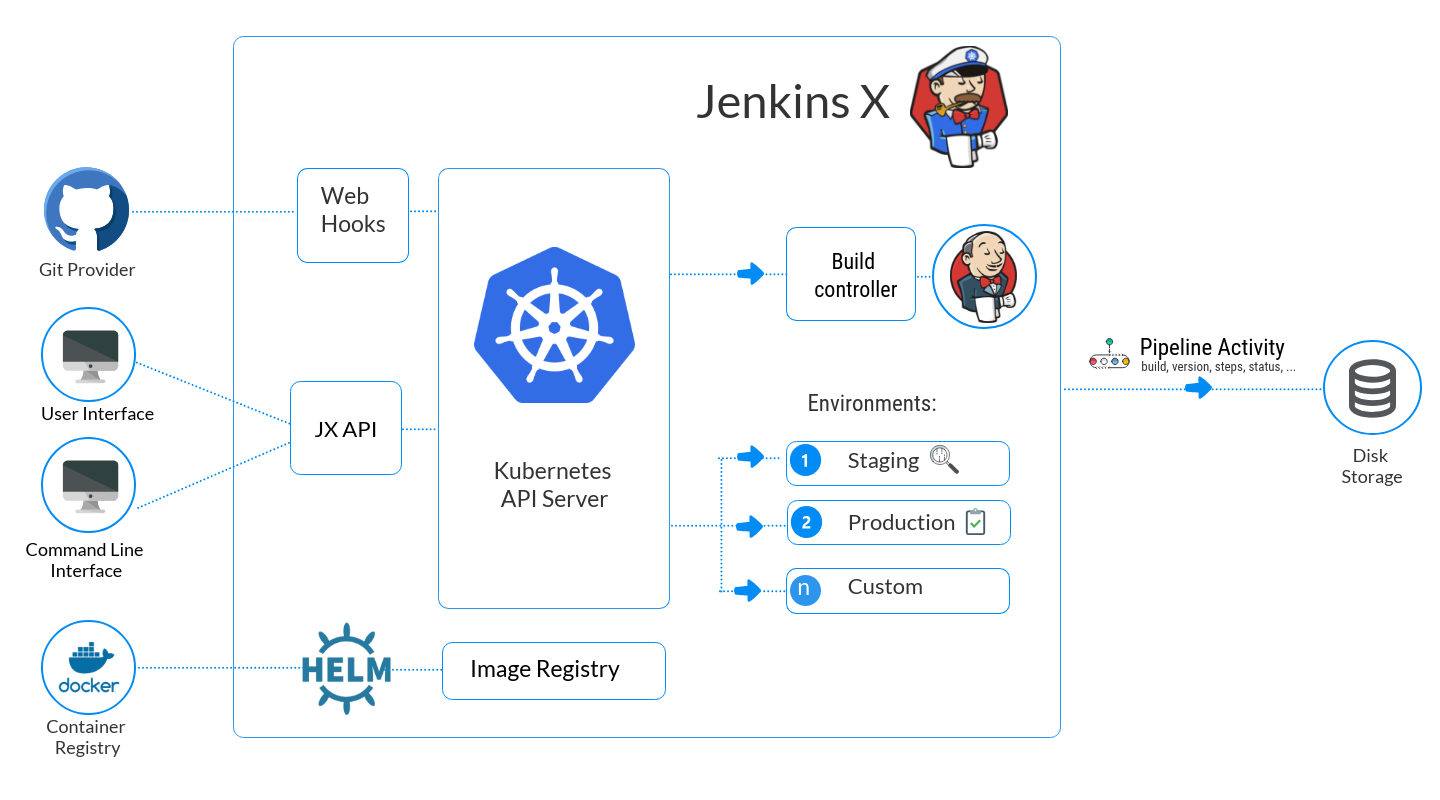
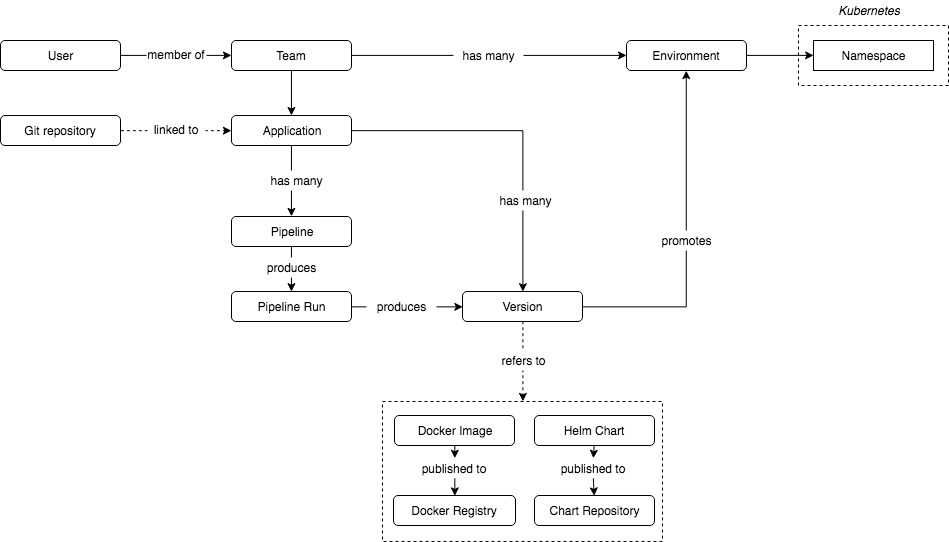
Jenkins X builds upon the following core components:
At the heart of the system is Kubernetes, which has become the defacto virtual infrastructure platform for DevOps. Every major Cloud provider now offers Kubernetes infrastructure on demand and the platform may also be installed in-house on private infrastructure, if required.
Functionally, the Kubernetes platform extends the basic Containerisation principles provided by Docker to span across multiple physical Nodes.
In brief, Kubernetes provides a homogeneous virtual infrastructure that can be scaled dynamically by adding or removing Nodes. Each Node participates in a single large flat private virtual network space.
The unit of deployment in Kubernetes is the Pod, which comprises one or more Docker containers and some meta-data. All containers within a Pod share the same virtual IP address and port space. Deployments within Kubernetes are declarative, so the user specifies the number of instances of a given version of a Pod to be deployed and Kubernetes calculates the actions required to get from the current state to the desired state by deploying or deleting Pods across Nodes. The decision as to where specific instances of Pods will be instantiated is influenced by available resources, desired resources and label-matching. Once deployed, Kubernetes undertakes to ensure that the desired number of Pods of each type remain operational by performing periodic health checks and terminating and replacing non-responsive Pods.
To impose some structure, Kubernetes allows for the creation of virtual Namespaces which can be used to separate Pods logically, and to potentially associate groups of Pods with specific resources. Resources in a Namespace can share a single security policy, for example. Resource names are required to be unique within a Namespace but may be reused across Namespaces.
In the Jenkins X model, a Pod equates to a deployed instance of a Microservice (in most cases). Where horizontal scaling of the Microservice is required, Kubernetes allows multiple identical instances of a given Pod to be deployed, each with its own virtual IP address. These can be aggregated into a single virtual endpoint known as a Service which has a unique and static IP address and a local DNS entry that matches the Service name. Calls to the Service are dynamically remapped to the IP of one of the healthy Pod instances on a random basis. Services can also be used to remap ports. Within the Kubernetes virtual network, services can be referred to with a fully qualified domain name of the form: <service-name>.<namespace-name>.svc.cluster.local which may be shortened to <service-name>.<namespace-name> or just <service-name> in the case of services which fall within the same namespace. Hence, a RESTful service called ‘payments’ deployed in a namespace called ‘finance’ could be referred to in code via http://payments.finance.svc.cluster.local, http://payments.finance or just http://payments, dependent upon the location of the calling code.
To access Services from outside the local network, Kubernetes requires the creation of an Ingress for each Service. The most common form of this utilises one or more load balancers with static IP addresses, which sit outside the Kubernetes virtual infrastructure and route network requests to mapped internal Services. By creating a wildcard external DNS entry for the static IP address of the load balancer, it becomes possible to map services to external fully-qualified domain names. For example, if our load balancer is mapped to *.jenkins-x.io then our payments service could be exposed as http://payments.finance.jenkins-x.io.
Kubernetes represents a powerful and constantly improving platform for deploying services at massive scale, but is also complex to understand and can be difficult to configure correctly. Jenkins X brings to Kubernetes a set of default conventions and some simplified tooling, optimised for the purposes of DevOps and the management of loosely-coupled services.
The jx command line tool provides simple ways to perform common operations upon Kubernetes instances like viewing logs and connecting to container instances. In addition, Jenkins X extends the Kubernetes Namespace convention to create Environments which may be chained together to form a promotion hierarchy for the release pipeline.
A Jenkins X Environment can represent a virtual infrastructure environment such as Dev, Staging, Production etc for a given code team. Promotion rules between Environments can be defined so that releases may be moved automatically or manually through the pipeline. Each Environment is managed following the GitOps methodology - the desired state of an Environment is maintained in a Git repository and committing or rolling back changes to the repository triggers an associated change of state in the given Environment in Kubernetes.
Kubernetes clusters can be created directly using the jx create cluster command, making it simple to reproduce clusters in the event of a failure. Similarly, the Jenkins X platform can be upgraded on an existing cluster using jx upgrade platform. Jenkins X supports working with multiple Kubernetes clusters through jx context and switching between multiple Environments within a cluster with jx environment.
Developers should be aware of the capabilities that Kubernetes provides for distributing configuration data and security credentials across the cluster. ConfigMaps can be used to create sets of name/value pairs for non-confidential configuration meta-data and Secrets perform a similar but encrypted mechanism for security credentials and tokens. Kubernetes also provides a mechanism for specifying Resource Quotas for Pods which is necessary for optimising deployments across Nodes and which we shall discuss shortly.
By default, Pod state is transient. Any data written to the local file system of a Pod is lost when that Pod is deleted. Developers should be aware that Kubernetes may unilaterally decide to delete instances of Pods and recreate them at any time as part of the general load balancing process for Nodes so local data may be lost at any time. Where stateful data is required, Persistent Volumes should be declared and mounted within the file system of specific Pods.
Interacting directly with Kubernetes involves either manual configuration using the kubectl command line utility, or passing various flavours of YAML data to the API. This can be complex and is open to human error creeping in. In keeping with the DevOps principle of ‘configuration as code’, Jenkins X leverages Helm and Draft to create atomic blocks of configuration for your applications.
Helm simplifies Kubernetes configuration through the concept of a Chart, which is a set of files that together specify the meta-data necessary to deploy a given application or service into Kubernetes. Rather than maintain a series of boilerplate YAML files based upon the Kubernetes API, Helm uses a templating language to create the required YAML specifications from a single shared set of values. This makes it possible to specify re-usable Kubernetes applications where configuration can be selectively over-ridden at deployment time.
What is Jenkins X?
An overview of the concepts in Jenkins X.
Matrix that describes the current state of Jenkins X capabilities for major Kubernetes platforms
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.